Ruby, Rails, and CircleCI 2.0

David Bernheisel, Former Developer
Article Categories:
Posted on
A guide to CircleCI 2.0 workflows with Rails apps for 2018
There's a movement lately in the development world that I've really enjoyed:
"Know your tools"
- probably tool authors
It's encouraged me to dive deeper into the tools that I use every day and understand more how they work.
- Ruby? I should know how OpenStruct works.
- Rails? I should understand the request cycle.
- SQL? I should understand database views and triggers.
- Git? I should understand how to rebase.
- CI? I should understand my tool of choice.
Why? Because it makes me a better developer. I expose myself to new patterns, learn new concepts, and have those solution-patterns in my toolbox for when I need to solve problems.
Today, I want to talk about my tool of choice for Continuous Integration.
CircleCI 2.0 #
My tool of choice for Continuous Integration lately is CircleCI 2.0. I've really enjoyed it. I don't think I went out of my way to pick them, honestly, but a couple of co-workers before me setup projects that I work on with CircleCI; I think they made a good choice.
Depending on how long ago the project was setup for CI, you might be using CircleCI 1.0 configurations, which is deprecating on EOD August 31, 2018.
Enter my problem: I had a project using CircleCI 1.0, so I needed to migrate quickly. Our deployment process also happens via CI, so I didn't want that to stop.
Time for me to dive into CircleCI.
What is CircleCI? #
I'll keep it short here, because they do a better job explaining who they are. CircleCI is a service that uses containers to build your code, test your code, and deploy your code.
What are containers? They are isolated environments that run software. CircleCI 2.0 uses containers to manage your code, and extends that container configurability to your projects.
How do I configure my container? #
This is the "know your tools" part. Thankfully, CircleCI provides a lot of great documentation and samples. Since this is an article about Ruby and Rails, using their Rails tutorial will be enough to get you going.
In their Rails tutorial, they are using one container to build your project and test your code. I could modify it to also deploy my project; it's simple to add another step:
# replace "production" with integration, staging, or whatever environment
# you need to deploy.
- run: git config --global user.name "CircleCI"
- run: bundle exec cap production deployUsing Capistrano makes it easy to deploy for most Rails applications. Above assumes you've configured the CircleCI project to have the appropriate SSH keys, so it can log into the server and perform the needed steps.
At this point you could be done if you're in the same boat as me and need to move off of CircleCI 1.0 and onto CircleCI 2.0. But, this isn't really about migrating from CircleCI 1.0 to CircleCI 2.0; we're here to learn!
Not everything has to be together #
I decided to explore a little further and use another CircleCI feature: workflows
In my development environment, everything happens on my machine. I like my machine because it's the way I made it. I like using brew to install dependencies, but the CI environment runs Linux which my production environment also runs.
CircleCI leverages containers to help keep "software units" separate and pure. This is smart because I need these environments to be accurately reproducible and not fragile to some other dependency being introduced. Have you ever installed a different version of OpenSSL to "fix" one project, but totally borked other projects on your machine? Containers prevent this problem.
When you think about what your CI process does, there's probably a couple of large tasks happening:
- Install language versions
- Install dependencies outside of your language (like imagemagick)
- Install dependencies in your language (with bundler)
- Install dependencies in your other language (with npm)
- Precompile assets
- Run Ruby tests
- Run JavaScript tests (you wrote those, right?)
- Run linting checks (your team agrees on the same style, right?)
- Deploy the test-approved and working code
With containers, we can separate these tasks. This has some benefits because we can run some of these in parallel instead of serially; that might give us a speed boost; more importantly, it communicates better where the failure is happening, if it happens.
Also, what if your Ruby tests fail? Wouldn't you also like to know if your JavaScript tests fail? Most of the CI scripts I've seen will stop on the first failed command which doesn't give you a complete picture.
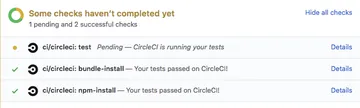
Gotta keep 'em separated #
For installing the language versions, I used to rely on tools like asdf and nvm and rbenv, but I realized that I shouldn't need to use those tools when using containers. I need those tools for my local development environment so I can switch between projects, but not when I can use a container image that has the language versions I need already installed for this project.
Enter: CircleCI docker images.
CircleCI provides some great container images with good tools included like dockerize, xvfb, and chromedriver, which saves you from having to worry about installing those manually. Let's use their images.
What is Dockerize? It's a small bash utility that is used to wait on database containers to be ready before trying to have tests run against them.
What is xvfb and chromedriver? Good question, I don't really understand it, but I know I need it to allow some browser tests to run. Just roll with it. Today, let's focus on learning about CircleCI and leave these tools for another day :)
In my case, my project is using Ruby 2.5.1 but unfortunately requires Node 6.x
because of an older node-based asset pipeline. CircleCI's Ruby image
Dockerfile includes Node 8.x, so I can't run npm install without issues.
That's OK though, because we can separate them with containers.
Let's try this out #
According to CircleCI docs, I'll need to define multiple jobs for a workflow. I'll try to keep the jobs focused on one task. Let's start with two tasks:
- Bundle Install
- NPM Install. The production environment doesn't use Yarn, so I shouldn't
either in CI yet. Also, Node 6.x doesn't ship with npm that supports
package-lock.json. I'll leave some commented-out code though in case you can use it.
jobs:
bundle-install:
working_directory: ~/repo
docker:
- image: circleci/ruby:2.5.1-node-browsers
environment:
BUNDLE_JOBS: 4
BUNDLE_RETRY: 3
BUNDLE_PATH: vendor/bundle
DATABASE_URL: "postgresql://root@localhost/my_project_test?pool=5"
steps:
- checkout
- attach_workspace:
at: ~/repo
- restore_cache:
keys:
- bundle-{{ arch }}-{{ checksum "Gemfile.lock" }}
# We add "arch" as a key since some gems compile native code, like
# nokogiri. If for whatever reason CircleCI runs the job on a machine
# with a different architecture, the cache would be invalid.
- run: bundle install
- save_cache:
paths:
- ./vendor/bundle
key: bundle-{{ arch }}-{{ checksum "Gemfile.lock" }}
- persist_to_workspace:
root: .
paths:
- vendor/bundle
npm-install:
working_directory: ~/repo
docker:
- image: circleci/node:6
steps:
- checkout
- attach_workspace:
at: ~/repo
# Enable when using npm5+
# - restore_cache:
# keys:
# - node-modules-{{ arch }}-{{ checksum "package-lock.json" }}
# We add "arch" as a key since some packages compile native code, like
# node-sass. If for whatever reason CircleCI runs the job on a machine
# with a different architecture, the cache would be invalid.
- run: npm --version
- run: node --version
- run: npm install
- run: mkdir -p public/assets/frontend
- run: npm run production
# Enable when using npm5+
# - save_cache:
# paths:
# - node_modules
# key: node-modules-{{ arch }}-{{ checksum "package-lock.json" }}
- persist_to_workspace:
root: .
paths:
- node_modules
- public/assets/frontendLooking good so far. I'm not doing anything special but there are a couple of concepts we should know:
- Cache: This is used to save dependencies across runs.
- Workspace: This is used to save data as the workflow continues, so the next
step can use the results of a previous step like
node_modulesandvendor/bundle. We attach the workspace at the beginning, and then persist some resulting files to the workspace at the end of the task.
For my project, when we run npm run production, it compiles assets into
the folder public/assets/frontend. I need that to run my tests later.
Let's move on to the test step:
test:
working_directory: ~/repo
docker:
# The first image is the primary image. This is where the commands below
# will run within.
- image: circleci/ruby:2.5.1-node-browsers
environment:
BUNDLE_JOBS: 4
BUNDLE_RETRY: 3
BUNDLE_PATH: vendor/bundle
DATABASE_URL: "postgresql://root@localhost/my_project_test?pool=5"
# For more information about how these images work, check our their READMEs
# https://hub.docker.com/r/circleci/ruby/
# https://hub.docker.com/r/circleci/postgres/
# https://hub.docker.com/_/postgres/
- image: circleci/postgres:9.3-alpine-ram
environment:
POSTGRES_USER: root
POSTGRES_DB: my_project_test
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: dockerize -wait tcp://localhost:5432 -timeout 1m
- run: cp config/secrets.yml{.example,}
- run: cp config/database.yml{.example,}
- run: bundle install
- run: RAILS_ENV=test bundle exec rake db:schema:load --trace
- run: |
mkdir -p ~/repo/tmp/test-results/rspec
bundle exec rspec --profile 10 --format RspecJunitFormatter --out ~/repo/tmp/test-results/rspec/results.xml --format progress
- store_artifacts:
path: ~/repo/tmp/screenshots
destination: test-screenshots
- store_test_results:
path: ~/repo/tmp/test-resultsSince we're attaching the workspace, we can assume that we have our
node_modules and vendor/bundle are already present. We still run bundle
install, but it's incredibly quick since the workspace already has the info--
bundler just needs to recognize it.
I want to point out another CircleCI feature: collecting test metadata.
There's a popular XML format for expressing test outputs and metadata, like the time it took to run each test; JUnit popularized this format. To get it for your tests, you can install a gem. All of the information is on the CircleCI site.
This feature gives us this:
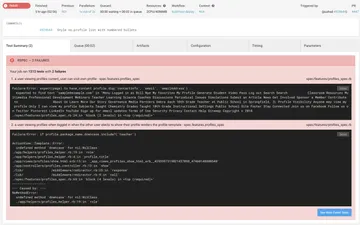
One more CircleCI feature: storing artifacts. I think this is normally for compiled binaries of your app, but I'm going to use it for storing screenshots of failed browser-based tests. Rails 5.1 system specs will do this automatically, but you can also add it to older Rails projects with capybara-screenshot. All we have to do is tell CircleCI where to find artifacts.
Ideally, you could set up two more jobs here:
- job:
lint-rubocop - job:
lint-eslint
But that's up to you.
Lastly, we need to deploy the app:
deploy-integration:
docker:
- image: circleci/ruby:2.5.1-node-browsers
environment:
BUNDLE_JOBS: 4
BUNDLE_RETRY: 3
BUNDLE_PATH: vendor/bundle
DATABASE_URL: "postgresql://root@localhost/my_project_test?pool=5"
- image: circleci/postgres:9.3-alpine-ram
environment:
POSTGRES_USER: root
POSTGRES_DB: my_project_test
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: bundle install
- run: |
git config --global user.name "CircleCI"
bundle exec cap integration deploy
# copy and paste and modify for each environmentNothing special here, but I do want to have CI identify itself as CircleCI for the Capistrano process that uses git. Just like before, above assumes you've configured the CircleCI project to have the appropriate SSH keys, so it can log into the server and perform the needed steps.
We've described the jobs, but we haven't described the workflow. Let's do that now.
Putting it together #
workflows:
version: 2
build-test-deploy:
jobs:
- bundle-install
- npm-install
- test:
requires:
- bundle-install
- npm-install
- deploy-integration:
requires:
- test
filters:
branches:
only: masterThis describes the shape of your workflow. bundle-install and npm-install
don't have any requirements, so they can run in parallel. test requires the
installation steps to succeed before it can run, and deploy-integration
requires the test step to succeed, and only run when CI is running from
a commit on the master branch.
That gives us this shape:
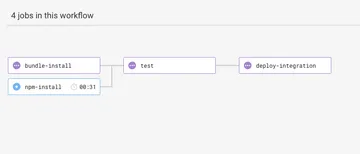
Remember, if you also linted the code and had JavaScript tests, you could have
4 jobs running in parallel since they don't depend on each other (only
npm-install and/or bundle-install)
YAML #
We can make it a little better with a little bit of YAML knowledge. With workflows, you'll repeat a lot of the same steps, and some of those steps can be verbose. We can help that.
For example, we repeated working_directory: ~/repo a lot, as well as the
docker images for several jobs. Let's shorten it with a named anchor.
defaults: &defaults
working_directory: ~/repo
docker:
- image: circleci/ruby:2.5.1-node-browsers
environment:
BUNDLE_JOBS: 4
BUNDLE_RETRY: 3
BUNDLE_PATH: vendor/bundle
DATABASE_URL: "postgresql://root@localhost/my_project_test?pool=5"
- image: circleci/postgres:9.3-alpine-ram
environment:
POSTGRES_USER: root
POSTGRES_DB: my_project_test
## and then use it like this:
jobs:
bundle-install:
<<: *defaults
steps: ...
test:
<<: *defaults
steps: ...
deploy-integration:
<<: *defaults
steps: ...Nice!
Encore: What if I fork the repo from the client? #
CircleCI is so helpful; they provide environment variables for you to check for situations like this. We can ask some questions against those variables with something like this:
deploy-integration:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: |
set -e
# only deploy from upstream
if [ "$CIRCLE_PROJECT_USERNAME" == "ClientName" ]; then
git config --global user.name "CircleCI"
bundle install
bundle exec cap integration deploy
fiJust add a dash of bash to make it work.
Wrapping up #
That concludes this episode of "know your tools". If you find anything wrong, another cool feature, or an alternative approach, then tweet @bernheisel with your recommendation.
By the way, there are other great CI platforms like Travis CI, GitLab, Google Cloud Build, and more. Today I'm using CircleCI, but tomorrow I might be trying out another platform. If above is way too much for you, I would consider looking at Travis CI; they did a great job simplifying to the essentials.
Here's the entire config file for my project. Feel free to modify it for yours!
# Ruby CircleCI 2.0 configuration file
#
# Check https://circleci.com/docs/2.0/language-ruby/ for more details
#
version: 2
defaults: &defaults
working_directory: ~/repo
docker:
- image: circleci/ruby:2.5.1-node-browsers
environment:
BUNDLE_JOBS: 4
BUNDLE_RETRY: 3
BUNDLE_PATH: vendor/bundle
DATABASE_URL: "postgresql://root@localhost/project_test?pool=5"
- image: circleci/postgres:9.3-alpine-ram
environment:
POSTGRES_USER: root
POSTGRES_DB: project_test
jobs:
bundle-install:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- restore_cache:
keys:
- bundle-{{ arch }}-{{ checksum "Gemfile.lock" }}
- run: bundle install
- save_cache:
paths:
- ./vendor/bundle
key: bundle-{{ arch }}-{{ checksum "Gemfile.lock" }}
- persist_to_workspace:
root: .
paths:
- vendor/bundle
npm-install:
working_directory: ~/repo
docker:
- image: circleci/node:6
steps:
- checkout
- attach_workspace:
at: ~/repo
# Enable when using npm5+
# - restore_cache:
# keys:
# - node-modules-{{ arch }}-{{ checksum "package-lock.json" }}
- run: npm --version
- run: node --version
- run: npm install
- run: mkdir -p public/assets/frontend
- run: npm run production
# Enable when using npm5+
# - save_cache:
# paths:
# - node_modules
# key: node-modules-{{ arch }}-{{ checksum "package-lock.lock" }}
- persist_to_workspace:
root: .
paths:
- node_modules
- public/assets/frontend
test:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: dockerize -wait tcp://localhost:5432 -timeout 1m
- run: cp config/secrets.yml{.example,}
- run: cp config/database.yml{.example,}
- run: bundle install
- run: RAILS_ENV=test bundle exec rake db:schema:load --trace
- run: |
mkdir -p ~/repo/tmp/test-results/rspec
bundle exec rspec --profile 10 --format RspecJunitFormatter --out ~/repo/tmp/test-results/rspec/results.xml --format progress
- store_artifacts:
path: ~/repo/tmp/screenshots
destination: test-screenshots
- store_test_results:
path: ~/repo/tmp/test-results
deploy-integration:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: |
set -e
# only deploy from upstream
if [ "$CIRCLE_PROJECT_USERNAME" == "ClientName" ]; then
git config --global user.name "CircleCI"
bundle install
bundle exec cap integration deploy
fi
deploy-staging:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: |
set -e
# only deploy from upstream
if [ "$CIRCLE_PROJECT_USERNAME" == "ClientName" ]; then
git config --global user.name "CircleCI"
bundle install
bundle exec cap staging deploy
fi
deploy-production:
<<: *defaults
steps:
- checkout
- attach_workspace:
at: ~/repo
- run: |
set -e
# only deploy from upstream
if [ "$CIRCLE_PROJECT_USERNAME" == "ClientName" ]; then
git config --global user.name "CircleCI"
bundle install
bundle exec cap production deploy
fi
workflows:
version: 2
build-test-deploy:
jobs:
- bundle-install
- npm-install
- test:
requires:
- bundle-install
- npm-install
- deploy-integration:
requires:
- test
filters:
branches:
only: master
- deploy-staging:
requires:
- test
filters:
branches:
only: staging
- deploy-production:
requires:
- test
filters:
branches:
only: production