Rdio / Spotify Conversion with Hubot and Slack
Mike Ackerman, Former Senior Developer
Article Category:
Posted on
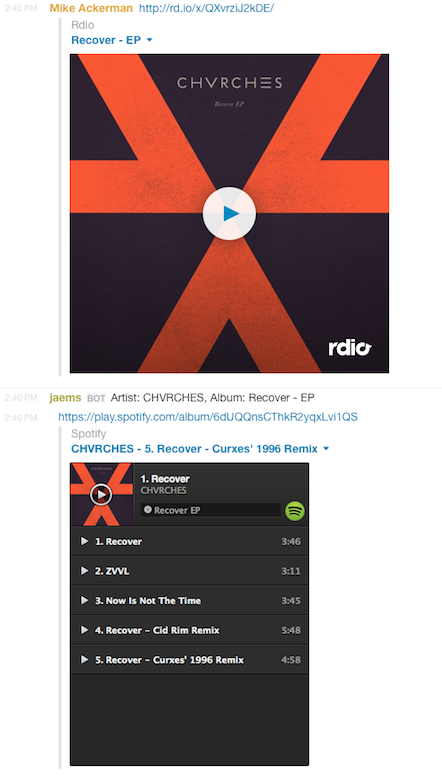
We love Slack at Viget. The #music channel is my favorite; it's great for finding new music or just discussing your favorite jam. Whenever we come across something we want to share, we grab the link from either Rdio or Spotify and paste into Slack. Because there's no clear preference between the two services, I developed some custom hubot scripts to convert the URLs from one service to another.
If you're just looking for the scripts, here you go:
- rdio_to_spotify.coffee.
- spotify_to_rdio.coffee. Make sure you also follow the link to include the required Rdio API scripts!
Rdio to Spotify
The detailed explanation:
Rdio links can come in two flavors: shortened (http://rd.io/x/...;) or long and descriptive (http://www.rdio.com/artist/.../album/.../track/...).
robot.hear /(https?:\/\/(www.)?(rd.?io).+)/i, (msg) ->
We first need to determine which type of link we're working with. When visiting a link of the shortened type, Rdio simply redirects to the longer full version (http://rd.io/x/QXvrziJ2kDE/ converts to https://www.rdio.com/artist/CHVRCHES/album/Recover_-_EP/). If the script determines it has a shortened URL, it makes an HTTP request to resolve the expanded URL.
if (msg.match[1].indexOf('http://rd.io/x/') != -1)
request
method: 'HEAD'
url: msg.match[1]
followAllRedirects: true
, (error, response) ->
expandedUrl = response.request.href
From there, we can parse the longer full version of the URL which has a consistent structure to determine: Artist, Album, and optionally Track.
artistFromUrl = (url) -> artist = '' artistMatch = url.match(/artist\/([^\/]*)/) artist = artistMatch[1].replace(/_/g,' ') if artistMatch != null return artist
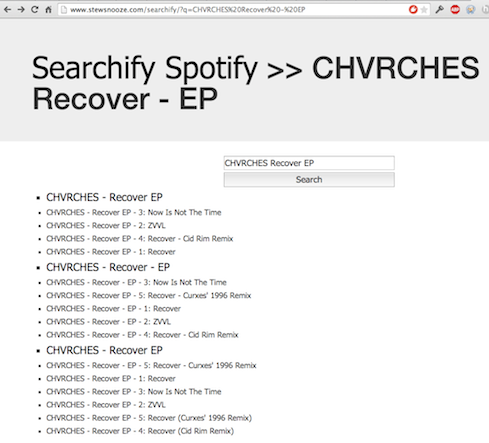
Using the Artist, Album, and Track information, we then use this great little Spotify search engine at: http://www.stewsnooze.com/searchify/. The included example will make a request like http://www.stewsnooze.com/searchify/?q=CHVRCHES+Recover%20-%20EP.
url = "http://www.stewsnooze.com/searchify/?q=#{artist}+#{album}+#{track}"
request url, (error, response, html) ->
unless error
# next: parse the response
Now that we have a page with results, we can use the cheerio node module which is a subset of jQuery in order to parse the HTML result content. It goes through one-by-one parsing the HTML to grab the link destination and text, and adding each to the results list. If there is an exact match, it will prefer that result and stop.
$ = cheerio.load(html)
$('.results').filter ->
data = $(this)
results = []
for result in data.children()
result = $(result)
if track != ''
trackMatch = result.html().match(/(spotify:track([^"])*)/)
resultText = "#{result.text()} -- #{convertSpotifyResultToLink(trackMatch[1])}"
results.push resultText if trackMatch != null
# check for an exact match
if result.text() == "#{artist} - #{album} - #{track}"
results = []
results.push resultText
break
convertSpotifyResultToLink = (result) ->
spotifyUrl = 'https://play.spotify.com/'
resultToken = result.match(/.+:(.+)$/)
if result.indexOf('spotify:track:') == 0
spotifyUrl += "track/#{resultToken[1]}"
else
spotifyUrl += "album/#{resultToken[1]}"
return spotifyUrl
Now that we have our results, we just have Hubot spit out the link!
if results.length > 1
result_count_line = "Found #{results.length} Spotify results"
msg.send "#{result_count_line}:\n #{results.join('\n')}"
else
msg.send results</code>
Spotify to Rdio

This conversion is a bit more complicated and requires using both the Spotify and Rdio APIs. You will need to create API applications for both types of API and configure your Hubot with the according client_id and client_secret for both API types (e.g. SPOTIFY_CLIENT_ID).
API documention can be found here: Spotify API Documentation and Rdio API Documentation.
API Application links: Spotify Applications and Rdio Applications
The detailed explanation:
Spotify links can come in a variety of flavors http://play.spotify.com/album/TOKEN or http://open.spotify.com/track/TOKEN. For example: http://open.spotify.com/track/4HGrOVrcNuoM0wQv3APnT8
robot.hear /(https?:\/\/(www.)?((play|open).spotify.com).+)/i, (msg) ->
The script first determines whether it's dealing with a Album or Track, and stores the token.
urlParseResults = searchTypeAndTokenFromUrl(url)
searchType = urlParseResults[0]
searchToken = urlParseResults[1]
searchTypeAndTokenFromUrl = (url) ->
token = ''
type = ''
if (url.indexOf('/track/') != -1)
type = 'track'
tokenMatch = url.match(/track\/([^\/]*)/)
token = tokenMatch[1] if tokenMatch != null
else if (url.indexOf('/album/') != -1)
type = 'album'
tokenMatch = url.match(/album\/([^\/]*)/)
token = tokenMatch[1] if tokenMatch != null
return [type, token]
Then, in order to work with the Spotify API it makes a request to get a fresh OAuth token.
refreshSpotifyAuthToken = (callback) ->
client_id = process.env.SPOTIFY_CLIENT_ID
client_secret = process.env.SPOTIFY_CLIENT_SECRET
basic_auth_base64_encoded = new Buffer("#{client_id}:#{client_secret}").toString('base64')
options = {
url: 'https://accounts.spotify.com/api/token',
method: 'POST',
headers: {
'Authorization': "Basic #{basic_auth_base64_encoded}"
},
form: { 'grant_type': 'client_credentials' }
}
request options, (error, response, body) ->
callback(JSON.parse(body).access_token)
Using the returned auth token, it can then do a lookup using the Spotify API using either of two API endpoints: tracks/TOKEN and albums/TOKEN.
spotifyApiLookup = (authToken, searchType, searchToken, callback) ->
url = "https://api.spotify.com/v1/#{searchType}s/#{searchToken}"
options = {
url: url,
headers: {
'Authorization': "Bearer #{authToken}"
}
}
request options, (error, response, body) ->
callback(body)
The API returns a JSON response including information about the Artist, Album, and potentially Track. This effectively converts that funky TOKEN value into what we need: 
Now that we've identified what the Spotify link means, we can use the Rdio API to find out if it has any matching songs. Using the provided rdio API javascript scripts, we can make a call to the Rdio API `search` method, with a `query` and `types` (Track or Album) parameters.
rdioAlbumFromSpotifyResponse = (response, callback) ->
# first get artist names and album from spotify API response
responseJson = JSON.parse(response)
artists = (artist.name for artist in responseJson.artists).join(" ")
album = responseJson.name
# search Rdio API
rdio.call 'search', { query: "#{artists} #{album}", types: "Album"}, (err, body) ->
callback(body)
Once we've got the response from the Rdio API and we can have our friendly hubot respond!
parseRdioResponseAndRespond = (response, message) ->
if parseInt(response.result.number_results) > 1
result_count_line = "Found #{response.result.number_results} Rdio results"
result_lines = ("#{result.name} - http://www.rdio.com#{result.url}" for result in response.result.results).join("\n")
message.send "#{result_count_line}:\n #{result_lines}"
else
result = response.result.results[0]
message.send "http://www.rdio.com#{result.url}"</code>
Find this useful? Developed anything similar? Please join the conversation below!